a gentle introduction to Kafka
Have you ever wondered how the systems of companies like Uber, Facebook, LinkedIn, and others interact with the enormous number of events happening simultaneously? And how can this data be processed in a way that ensures it isn’t lost? Or that it’s processed in the correct order, according to the time it occurred? All this and more can be achieved using Apache Kafka!
What is Kafka?
Kafka can be seen as a mailbox for the messages your system needs and handles. Imagine a post office that can process millions of messages in a short time within a well-organized system, while also giving you insurance on your messages — that they are saved and not easily lost. Additionally, it allows you to subscribe to promotional newsletters, which means the same newsletter reaches more than one consumer/recipient. Everything mentioned is an example of one of Kafka’s features.
Kafka is an open-source tool used for event streaming and processing, it is also sometimes called a message queue. It is famous for its use in situations that require processing a large amount of data in near real-time or even processing it asynchronously.
An Online Store and Millions of Users
Before we begin, let’s assume you have a platform that started as a simple online store, but after your promotional activities, the store’s visitors grew to the millions. When an order is made, the order service OrderService is called. This service, in turn, performs several operations synchronously:
- First, it calls the
InventoryServiceto reserve or update the product quantity. - When the first operation succeeds, the
PaymentServiceis called to process the payment. - When the payment is successful, the
NotificationServiceis called to send a order confirmation email to the user.
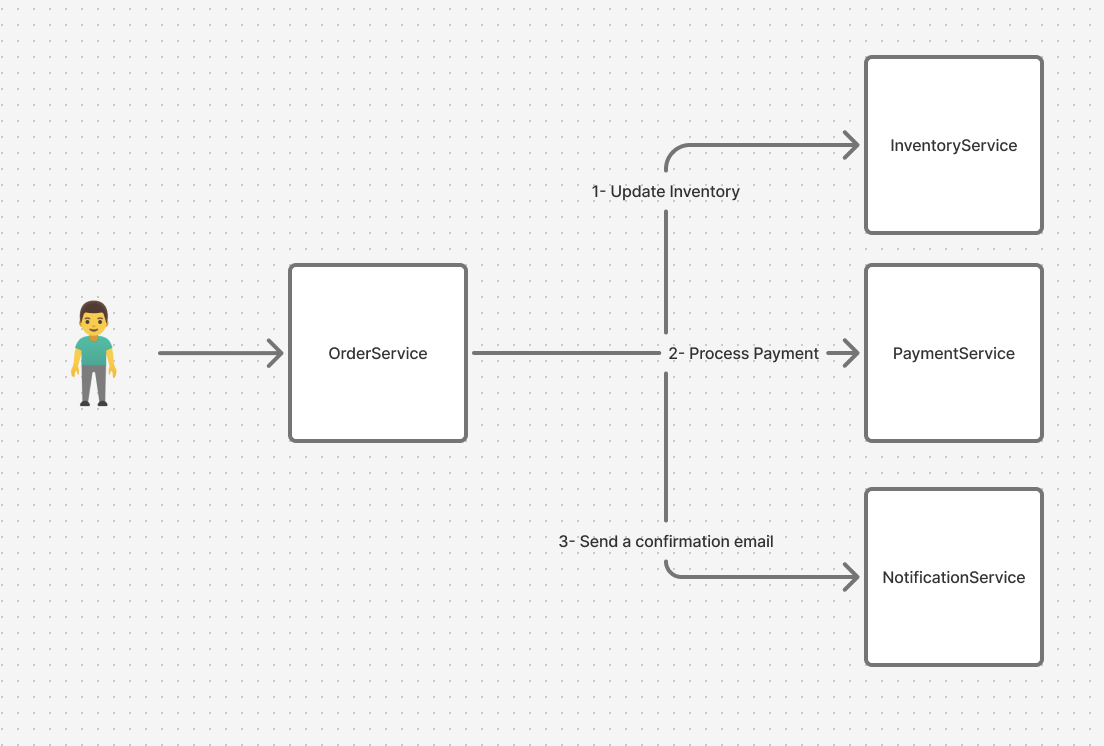
The above operations are done in order, and any failure in one of them causes a failure in the entire purchase process. This is called tight coupling between these services, and it is usually one of the causes of problems in large and complex software architectures (specifically, when there are many interacting services, this error often occurs naturally).
So, how can we redesign this architecture in a way that guarantees the process completes even if the notification service fails? And how can the efficiency of the OrderService be improved? In its current state, every operation in the order service means three synchronous internal operations, and it has to wait until these operations are successfully completed.
The Core Concepts in Kafka
Kafka’s internal structure is a bit complex, and this article will not dive into all its details, but we will present four basic concepts: producers, topics, brokers, and consumers.
Producers
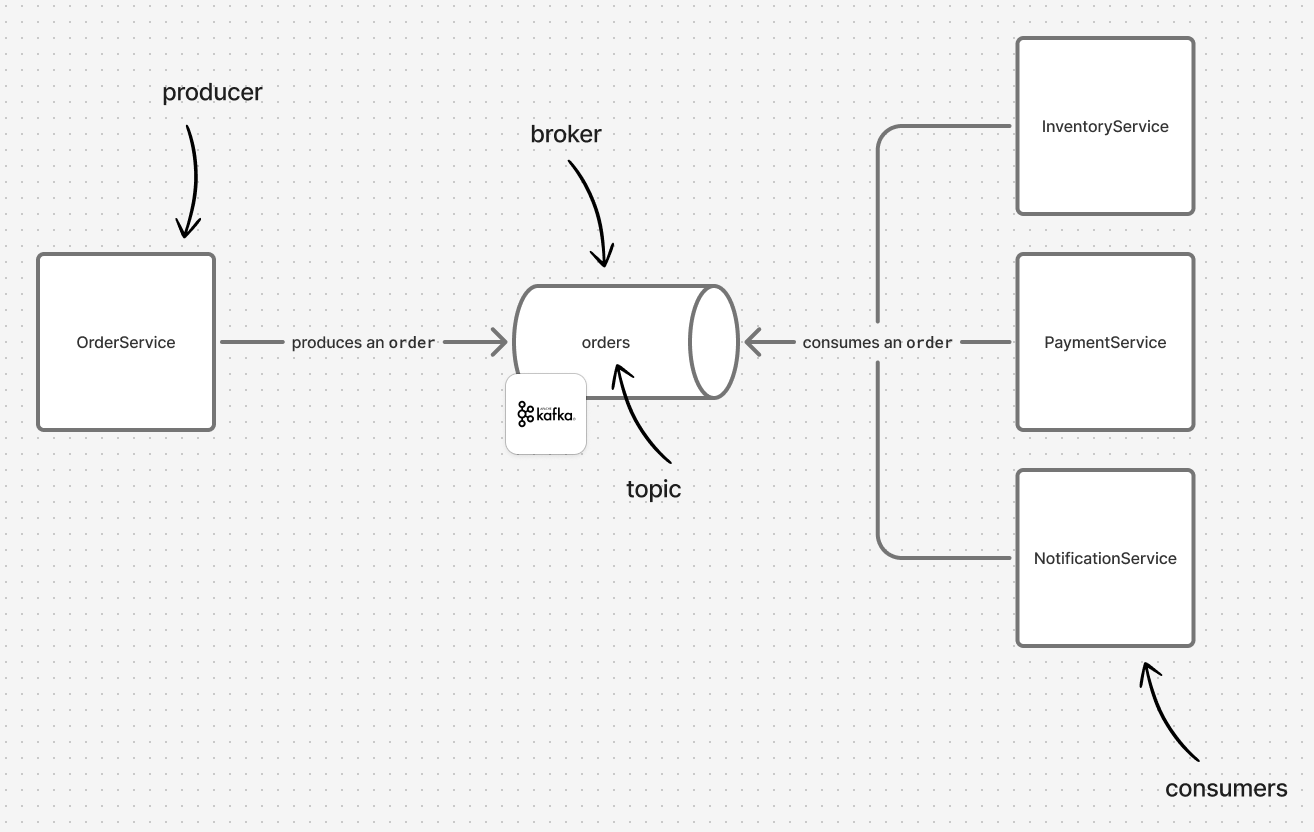
A producer is the component that contains the source of the information to be streamed or produced. In the example above, the producer might be the OrderService. When a user places an order, all the OrderService has to do is broadcast this event (under the orders topic, for example) to the brokers, who will then handle delivering this information to the other services that need it.
Brokers
Brokers can be thought of as a database (and it is very similar to one, as Kafka retains information on the disk and not in memory, and this is one of Kafka’s most important features), and they are the core of Kafka. Producers send messages to be saved by the brokers, who can then identify the intended recipients for those messages. To organize these messages, they are stored in Topics.
Topics
As mentioned earlier, messages are stored with brokers in Topics, which are much like tables in a database. Topics do not enforce a specific schema for messages, nor do they perform any validation of the expected information—this is for the consumer to do. All the brokers do is organize messages into topics and deliver them to the relevant consumer.
Returning to the previous example, we mentioned that the OrderService can broadcast a order event to the orders topic, and the brokers handle its delivery. From this, it can be inferred that the consumer must be aware of the topic to which it needs to subscribe.
Consumers
Consumers are the services that listen to the events they care about. In the example above, the consumers are the InventoryService, the PaymentService, and the NotificationService. Each of them listens for any new event in the orders topic, and when a purchase/order occurs, this event is processed in each of those services separately. If one of them fails, that failure will not affect the other operations. One of Kafka’s features is that a consumer can be reset to the point where it failed, so the problem can be fixed and the consumer can reprocess that message again.
How Kafka Solves Tight Coupling: A Fraud Detection Service
Let’s say you decide to add a new service to detect fraud in orders. This service works by analyzing each order and comparing it with previous operations, or by feeding the order operation with some additional inputs into a machine learning model to analyze whether there is fraud in this process. This means this service needs to know about every order that happens on the site. Returning to our example, the OrderService would need to call this new service after every order = a modification to the OrderService = a new deployment of this service, etc. This is tight coupling between services, and any change to one means a change to the other.
With Kafka, there is no need for all of this. All you have to do is create a new service that registers as a consumer of the orders topic mentioned above. The fraud detection service consumes the order events immediately, processes them, and determines if there is any fraud.
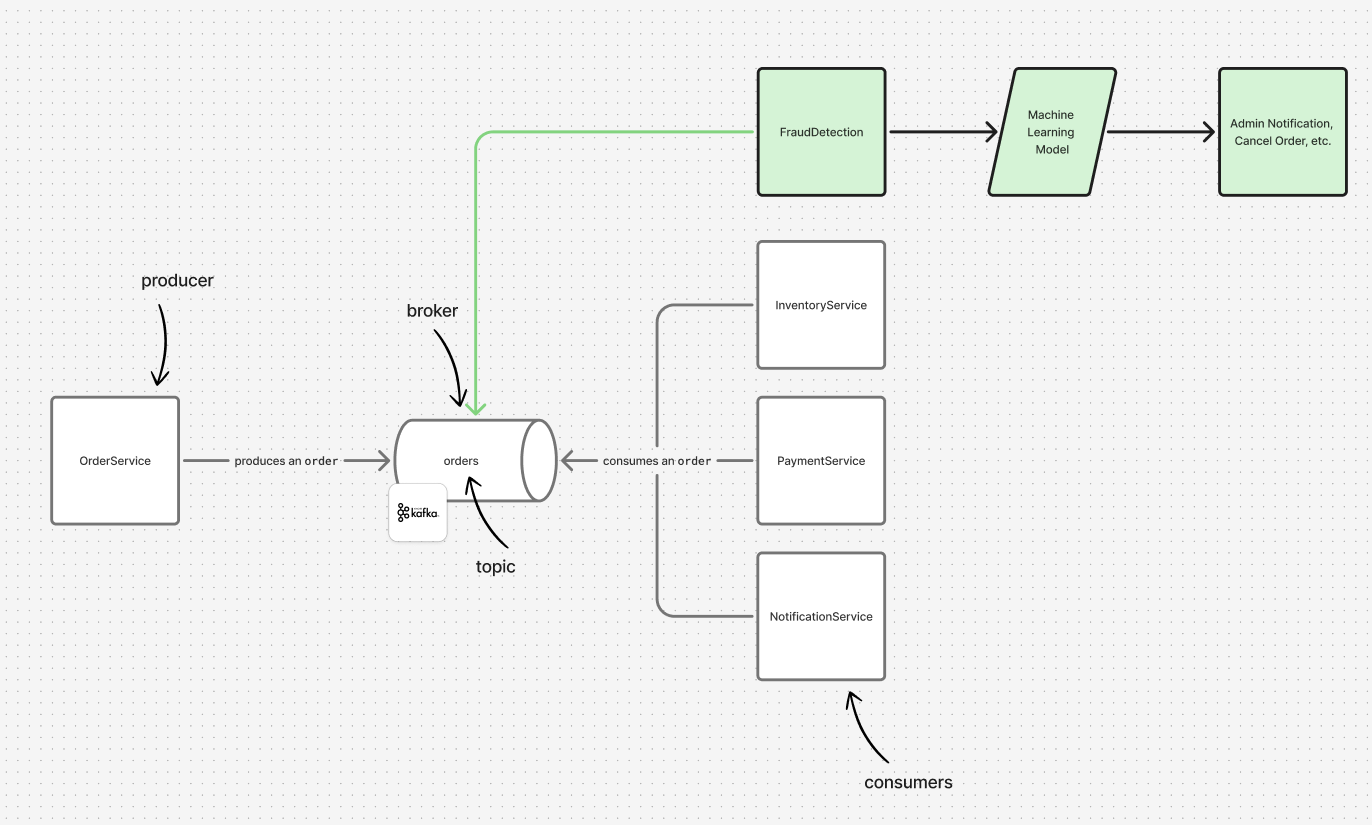
Other Examples
Based on what has been mentioned, you could add a service to determine delivery logistics, for example, without relying on the previous services. The new service would be a consumer of the same topic, reading the messages/events and reacting accordingly.
One of Kafka’s most famous uses is also log analysis, and Kafka can interact very smoothly with Elasticsearch—a database specialized for text search. Each of your services would acts as a producer, and Elasticsearch can consume these events via Kibana to create a large database of all your service logs.
Also, Kafka can be used to train machine learning models in a near real-time (or even asynchronous) manner. The learning service would be a consumer of topics containing important inputs for this model, and the model’s weights are updated based on the inputs.
There are many other uses, not limited to the concepts we have mentioned, using tools like Kafka Streams, for example, which is a tool integrated into Kafka that allows for pragmatic and seamless stream processing. There is also Apache Flink, which also works on stream processing in its own unique way (stateful stream processing).
Demo application using Spring Boot
The code for a demo in Spring Boot can be found in: https://github.com/mohammedamarnah/kafka-spring-boot-demo which contains a practical example using Java Spring Boot for all the concepts we mentioned in this article, including the consumer and producer. To make it easier, here are some of the important files in the program above:
- First,
KafkaProducerConfig, which contains the producer’s settings, such as the method of serializing the sent message (and this is an example of the need to ensure agreement between the producer and consumer on the message format, shape, etc.). - Second,
SampleKafkaProducer, which is the producer that contains the function that can be used when sending a message to the broker via a specific topic. - Next,
KafkaConsumerConfig, which contains a set of settings that can be specified for the consumer, such as how to deserialize the message (raw text, JSON, etc.). - Finally,
SampleKafkaConsumer, which contains the consumer and the logic that is executed when a new message is received.
I have added a Docker compose file to the repository above that contains images for Kafka and a very useful user interface that can also be used for other purposes such as sending messages to the consumer. If you follow the instructions in the repository above, you can use this interface via: http://localhost:8081/
You can send a message to the consumer via: http://localhost:8081/ui/clusters/local/all-topics/sample-topic and clicking the “Produce Message” button.
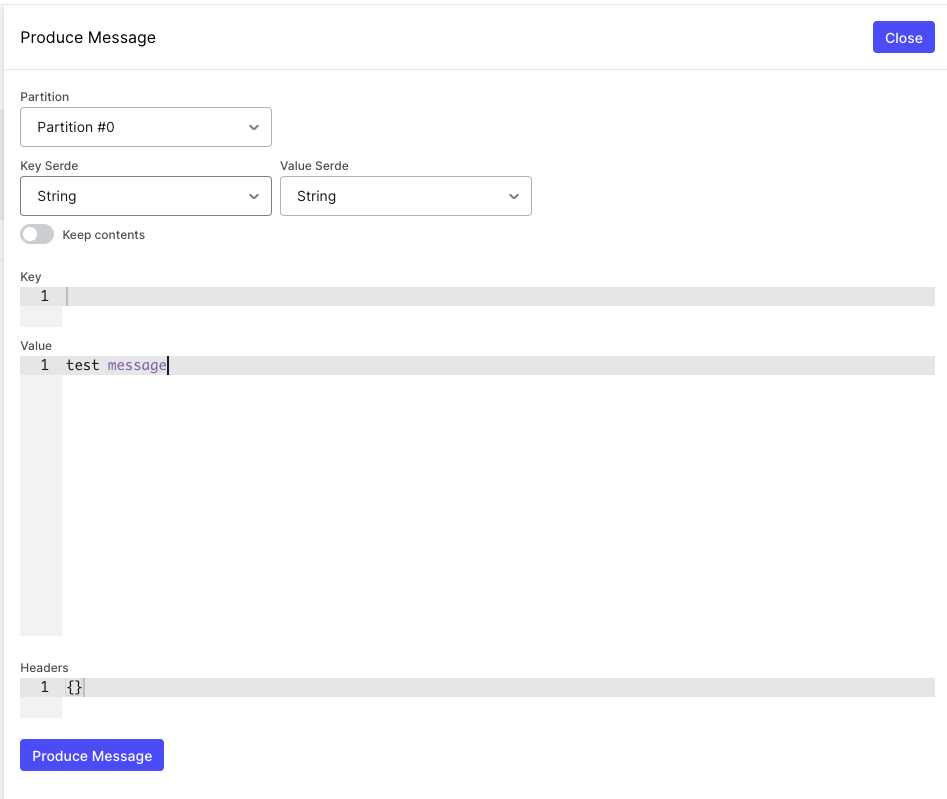
And you’ll see the message in the logs

Sources
- The original research paper published on Kafka: https://notes.stephenholiday.com/Kafka.pdf
- The official Kafka website itself contains several noteworthy resources (although I have not read most of them): https://kafka.apache.org/books-and-papers
- The “Jordan has no life” channel is a bit funny and has several videos about Kafka. In one video, he does a deep dive into Kafka and the original paper: http://www.youtube.com/watch?v=KGNlY7V9xA8