why is Clojure a token-efficient programming language?
I recently came across an article talking about some of the most “token-efficient” programming languages, in which Clojure came on top. The article doesn’t dive too deep into the “why” that is the case, so here’s an analysis (I wish I could say backed by research or data, but this is just a personal philosophical view that might be largely inaccurate or incorrect) on why a programming language like Clojure or Ruby might be as token-efficient as they are.
Higher Level of Abstraction == Dense Semantic Content Per Token
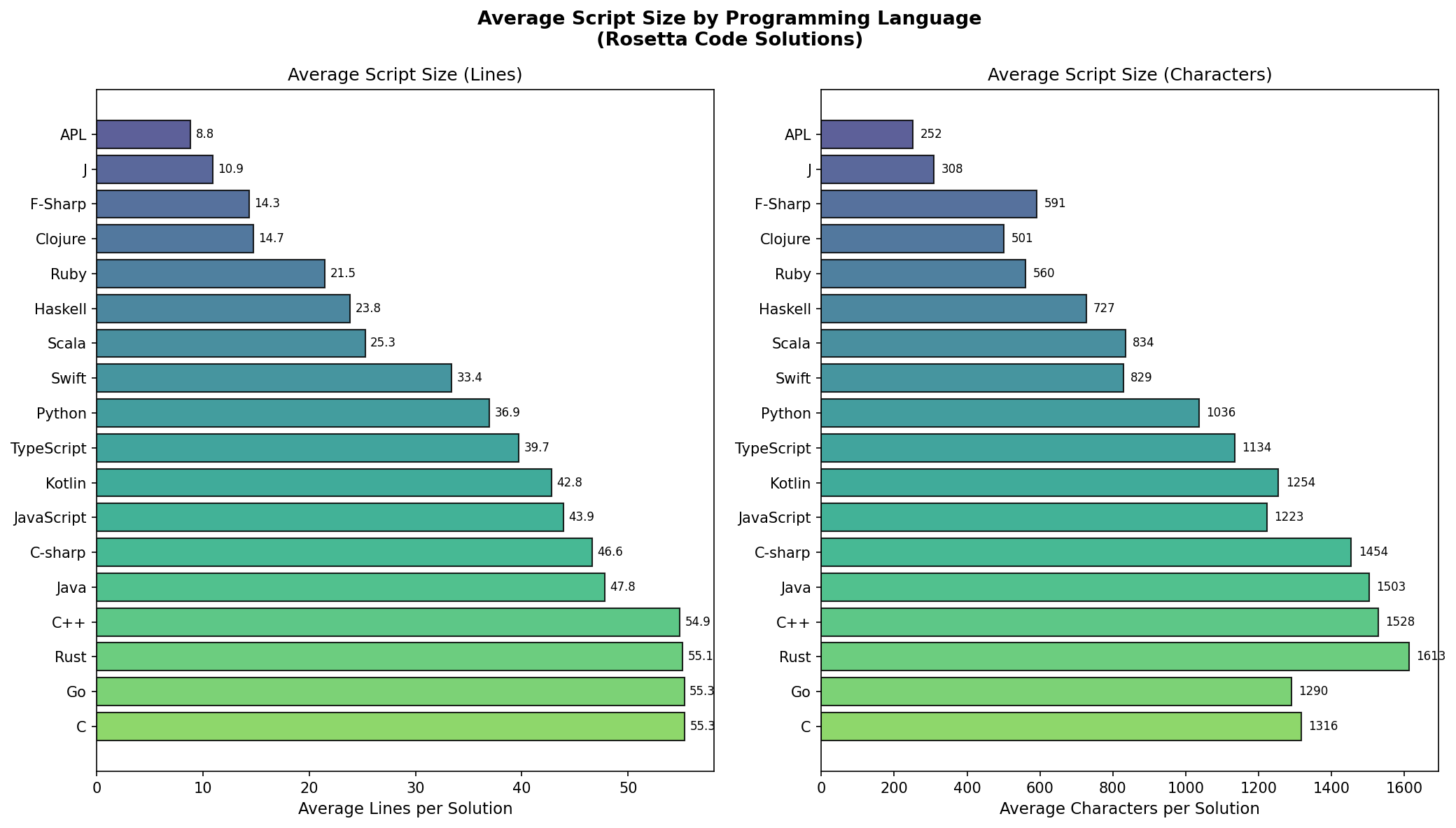
“Average tokens per task” could be interpreted as an indication of the average script length/size in a certain language. I ran another analysis to generate the average line count and character count per task per language, and you can see it correlates nicely with the original results from Martin’s article. Clojure comes on top with an average of 14 lines or 501 characters per solution, compared to C++ at 54 lines or 1528 characters per solution.
Programming languages like Clojure or Ruby offer a very high level of abstraction in which their standard library methods could do what other languages require you to implement manually.
Higher level of abstraction also means closeness to natural language, which LLMs are definitely optimized for. It’s probably easier and quicker for an LLM to reason through this in Clojure
(group-by even? (0 1 2 3 4 5 6 7 8 9))
;;=> {true [0 2 4 6 8], false [1 3 5 7 9]}than this in C++ (and I tried to be as explicit and concise at the same time as possible, omitting std, not initializing properly, not including error checks, etc.)
vector<int> list = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
map<bool, vector<int>> groupedList;
for (auto el : list) groupedList[el % 2 == 0].push_back(el);If you were someone with 0 programming knowledge, which one will you be able to reason through quicker? Just reading the words group by even?, you will get a rough idea on what is happening.
Our whole life, advancements in dealing with computers and software were mostly about abstractions. Abstractions means a more dense semantic content per token. That is, each token in a language with higher abstraction carries more information than what is in a language closer to the hardware.
Code-as-data
Lisp’s defining feature is that code and data share the same structure: both are S-expressions. LLMs can more easily generate syntactically valid Lisp because the uniform tree structure is simpler to parse and validate (More on its tree structure in the sections to come).
One example is Clojure’s quote '. It returns the language expression without evaluating it that allows for manipulating the code itself. Because code is data.
'(+ 1 2)
;;=> (+ 1 2) instead of 3The REPL (Read Eval Print Loop)
The REPL is a tool in Clojure that allows you to manipulate and interact with the source code during runtime. This is a powerful tool, and is known to greatly enhance the productivity of developers using it. A recent arXiv paper proposed that embedding LLMs within a persistent Lisp REPL allowed the model to dynamically create its own tools through meta-programming.
AST & Lisp’s Tree Structure
I am no expert in coding agents, but I believe there must be an AST (Abstract Syntax Tree) parsing for the languages somewhere and in at least some coding agents. Another arXiv paper shows that tree-based transformers using AST encoders perform better in code generation than others.
Clojure’s syntax is essentially already a tree.
(+ 1 (* 2 3))Is:
+
/ \
1 *
/ \
2 3This eliminates the gap between surface syntax and tree structure, making it trivial to parse and manipulate. It also helps LLMs understand code dependencies and relationships.
Overall, and based on the above, I think Clojure or Lisp, might be one of the most favorable languages for LLMs and humans in the future. It offers a good middle-ground between what humans can understand (vs. a language that only LLMs/coding agents can understand), and the ease of parsing and reasoning through for LLMs.
Martin’s article: https://martinalderson.com/posts/which-programming-languages-are-most-token-efficient/